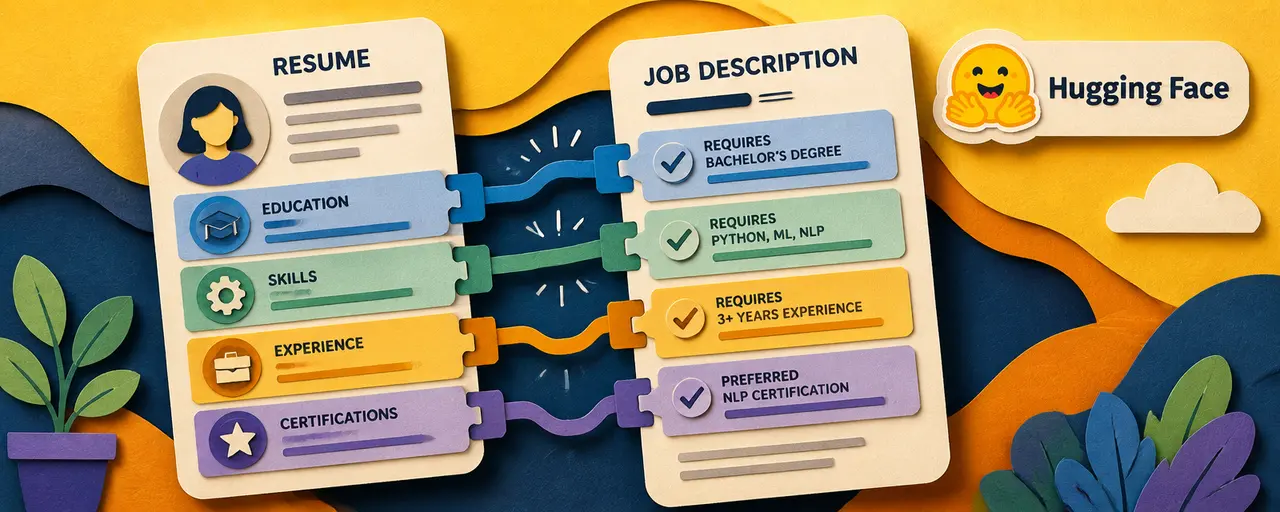
Поиск работы после вуза занимает месяцы и сотни бессмысленных откликов. Hugging Face опубликовал Job Searcher — инструмент, где дообученная Qwen3-8B читает резюме, сама формулирует поисковые запросы в LinkedIn и выдаёт короткий шортлист с пятимерной оценкой по каждой вакансии.
Пайплайн дистилляции строится на паре учитель — ученик. Учитель — DeepSeek V4 Pro (1.6 трлн параметров): он сгенерировал LinkedIn-запросы под каждое из 2 500 резюме, прогнал их через библиотеку JobSpy и получил около 10 000 вакансий. Затем тот же учитель оценил каждую пару (резюме, вакансия) по пяти осям:
- Навыки — совпадение требований с опытом кандидата.
- Релевантность опыта — насколько прошлые роли подходят под позицию.
- Образование и сертификаты — соответствие формальным требованиям.
- Отрасль и домен — совпадение индустрии.
- Грейд — соответствие уровня позиции.
К каждой оси — одна строка обоснования. Эти размеченные данные стали обучающей выборкой для Qwen3-8B.
Саму Qwen3-8B дообучили двумя LoRA SFT-прогонами (rank 16, alpha 16, по одной эпохе каждый) на одном A100 через Modal. Итоговые веса лежат в safetensors и Q4_K_M GGUF. Space работает на ZeroGPU через llama-cpp-python: все оценки одного резюме проходят внутри одного GPU-вызова, рассуждения стримятся токен за токеном.
Есть один нетривиальный архитектурный момент для тех, кто будет воспроизводить. Llama-инстанс нужно создавать внутри декоратора @spaces.GPU, а не на уровне модуля — иначе ZeroGPU уничтожает CUDA-контекст между вызовами и второй запрос падает.
Замкнутый цикл выглядит так: большая модель генерирует данные и расставляет метки, маленькая их усваивает и работает бесплатно на ZeroGPU. Шаблон переносится на любую задачу с парами (документ A, документ B) — оценка резюме и вакансии здесь не уникальна. Честный пробел: авторы не приводят ни бенчмарка, ни пользовательского теста — насколько шортлист реально лучше случайного отбора, проверить пока нечем.